flashtext:大规模文本数据清洗利器
以下文章来源于大邓和他的Python
前言
做 文本分析时候经常遇到同意多形词,如 BigApple/NewYork/NN 都可能代指纽约市, 当我们统计纽约市出现的次数的时候我们需要分别统计这三个词的数目并进行加总。
flashtext对于处理上面的问题非常擅长,而且运算速度特别快。清洗数据的速度,我们可以拿正则表达式来和flashtext作比较
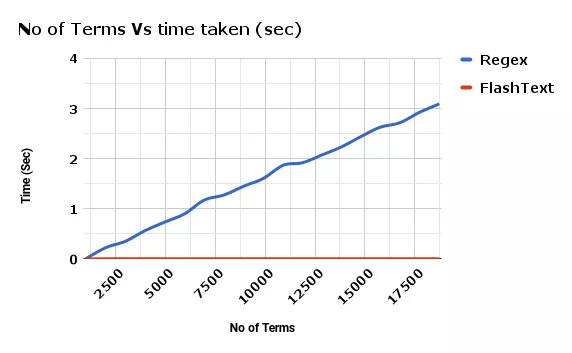
我们发现运行正则表达式来清洗数据,速度会随着数据量线性下降,而flashtext的清洗性能基本保持不变。
一、安装
- pip3 install flashtext
二、官方文档
- https://flashtext.readthedocs.io/en/latest/
三、常用用法
3.1 不清洗,直接提取关键词
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love big Apple and Bay Area.')
keywords_found
Run
['Big Apple', 'Bay Area']
3.2 同义词指代,抽取关键词
像big apple 和new york都代指纽约,我们需要先清洗好数据,统一用一个词语代指纽约,再去抽取关键词语。这就用到 add_keyword方法。
from flashtext import KeywordProcessor
kw_processor = KeywordProcessor()
#给关键词处理器对象中加入待识别的关键词
kw_processor.add_keyword('Big Apple', 'New York')
kw_processor.add_keyword('Bay Area')
#对文本数据进行关键词提取
kws_found = kw_processor.extract_keywords('I love Big Apple and Bay Area.')
kws_found
Run
['New York', 'Bay Area']
3.3 多个同义词指代
如果同义词太多,可以用字典构建映射关系。使用到的方法是addkeywordsfrom_dict
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_dict = {"java": ["java_2e", "java programing"],
"product management": ["PM", "product manager"]}
#从字典中加入映射关系
keyword_processor.add_keywords_from_dict(keyword_dict)
#从列表中加入关键词
keyword_processor.add_keywords_from_list(["java", "python"])
keyword_processor.extract_keywords('I am a product manager for a java_2e and python platform')
Run
['product management', 'java', 'python']
3.4 移除关键词
有的时候我们可能加错了关键词,想去除之前添加的关键词。这就用到removekeyword/removekeywords/removekeywordsfromdict/removekeywordsfromlist
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_dict = {
"java": ["java_2e", "java programing"],
"product management": ["PM", "product manager"]}
keyword_processor.add_keywords_from_dict(keyword_dict)
print(keyword_processor.extract_keywords('I am a product manager for a java_2e platform'))
keyword_processor.remove_keyword('java_2e')
keyword_processor.remove_keywords_from_dict({"product management": ["PM"]})
keyword_processor.remove_keywords_from_list(["java programing"])
keyword_processor.extract_keywords('I am a product manager for a java_2e platform')
Run
['product management', 'java']
['product management']
3.5 关键词个数
查看自定义的关键词个数
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_dict = {
"java": ["java_2e", "java programing"],
"product management": ["PM", "product manager"]
}
keyword_processor.add_keywords_from_dict(keyword_dict)
print(len(keyword_processor))
Run
4
3.6 判断某个词是否存在于关键词处理器中
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('j2ee', 'Java')
print('j2ee' in keyword_processor)
Run
True
add_keyword()中的传入的顺序不同,结果也不同
print(keyword_processor.get_keyword('j2ee'))
print(keyword_processor.get_keyword('Java'))
Run
Java
None
这个比较简单
keyword_processor['colour'] = 'color'
print(keyword_processor['colour'])
Run
color
3.7 获取关键词映射关系
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('j2ee', 'Java')
keyword_processor.add_keyword('colour', 'color')
keyword_processor.get_all_keywords()
Run
{'j2ee': 'Java', 'colour': 'color'}
3.8 替换关键词
from flashtext import KeywordProcessor
kw_processor2 = KeywordProcessor()
# 给关键词处理器对象中加入待识别的关键词
kw_processor2.add_keyword('New Delhi', 'NCR region')
kw_processor2.add_keyword('Big Apple','New York') # 注意顺序
#对文本数据进行关键词替换
new_sentence = kw_processor2.replace_keywords('I love Big Apple and new delhi.')
new_sentence
Run
'I love New York and NCR region.'
3.9 关键词的位置
flashtext还能计算待考察词语的开始与结束的索引值
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love big Apple and Bay Area.', span_info=True)
keywords_found
Run
[('New York', 7, 16), ('Bay Area', 21, 29)]
3.10 额外的信息
根据关键词,还能抽取一些额外的信息,如时间、位置等。但这些功能在中文中可能不太适用,英文问题不大。
from flashtext import KeywordProcessor
kp = KeywordProcessor()
kp.add_keyword('Taj Mahal', ('Monument', 'Taj Mahal'))
kp.add_keyword('Delhi', ('Location', 'Delhi'))
kp.extract_keywords('Taj Mahal is in Delhi.')
Run
[('Monument', 'Taj Mahal'), ('Location', 'Delhi')]
数据处理小工具
1.数据处理小工具
1. 删除多列数据
def drop_multiple_col(col_names_list, df):
'''
AIM -> Drop multiple columns based on their column names
INPUT -> List of column names, df
OUTPUT -> updated df with dropped columns
------
'''
df.drop(col_names_list, axis=1, inplace=True)
return df
有时,并不是所有列都对我们的分析有用。因此,df.drop函数是一个得心应手的工具去移除你指定的列。
2. 改变数据类型
def change_dtypes(col_int, col_float, df):
'''
AIM -> Changing dtypes to save memory
INPUT -> List of column names (int, float), df
OUTPUT -> updated df with smaller memory
------
'''
df[col_int] = df[col_int].astype('int32')
df[col_float] = df[col_float].astype('float32')
当一个数据集变大时,为了,我们需要dtypes 。如果你对学习如何用Pandas处理大型数据感兴趣, 我强烈建议你看一看这篇文章——为什么和如何用Pandas处理大型数据。
3. 将类别变量转为数值变量
def convert_cat2num(df):
# Convert categorical variable to numerical variable
num_encode = {'col_1' : {'YES':1, 'NO':0},
'col_2' : {'WON':1, 'LOSE':0, 'DRAW':0}}
df.replace(num_encode, inplace=True)
有些机器学习模型要求变量为数值形式。这时,在把数据输入进模型前,我们需要将类别变量转为数值变量。 对于数据可视化,我建议维持类编变量以便有一个更直观的解释和理解。
4. 检查丢失数据
def check_missing_data(df):
# check for any missing data in the df (display in descending order)
return df.isnull().sum().sort_values(ascending=False)
如果你想检查每列中丢失数据的数量,这是最快速的方法。这给你一个更好的用以理解哪些列有更多数量的丢失数据, 可以决定下一步数据清理和分析的方向。
5. 在列中移除字符串
def remove_col_str(df):
# remove a portion of string in a dataframe column - col_1
df['col_1'].replace('\n', '', regex=True, inplace=True)
# remove all the characters after &# (including &#) for column - col_1
df['col_1'].replace(' &#.*', '', regex=True, inplace=True)
有些时候,在你字符串类型的列中,你可能要面对换行符或是奇怪的符号的出现。这个问题可以被df[‘col_1’].replace轻松解决, 其中,col_1指的是数据帧中的某列。
6. 在列中移除空格
def remove_col_white_space(df,col):
# remove white space at the beginning of string
df[col] = df[col].str.lstrip()
当数据混乱时,任何事都有可能。所以列中字符串前有空格的情况时有发生。因此,如果你想移除它们时,这个办法很管用。
7. 用字符串(在指定条件下)合并列
def concat_col_str_condition(df):
# concat 2 columns with strings if the last 3 letters of the first column are 'pil'
mask = df['col_1'].str.endswith('pil', na=False)
col_new = df[mask]['col_1'] + df[mask]['col_2']
col_new.replace('pil', ' ', regex=True, inplace=True) # replace the 'pil' with emtpy space
当你想通过字符串把两列有条件的合并时,这个办法便派上用场。譬如,你想把第一列和第二列合并, 条件是根据第一列中以特定字母们结束的字符串。在合并后,根据你的需要,末尾字母们也可被移除。
8.转换时间戳(从string到datetime类型)
def convert_str_datetime(df):
'''
AIM -> Convert datetime(String) to datetime(format we want)
INPUT -> df
OUTPUT -> updated df with new datetime format
------
'''
df.insert(loc=2, column='timestamp', value=pd.to_datetime(df.transdate, format='%Y-%m-%d %H:%M:%S.%f'))
当处理时间序列数据时,这意味着我们很可能要将string格式转换到datetime格式——基于我们要求的特定格式—— 以便用数据做出有意义的分析和演示。